Volver al portafolio
Pipeline de Predicción de Emisiones de CO2
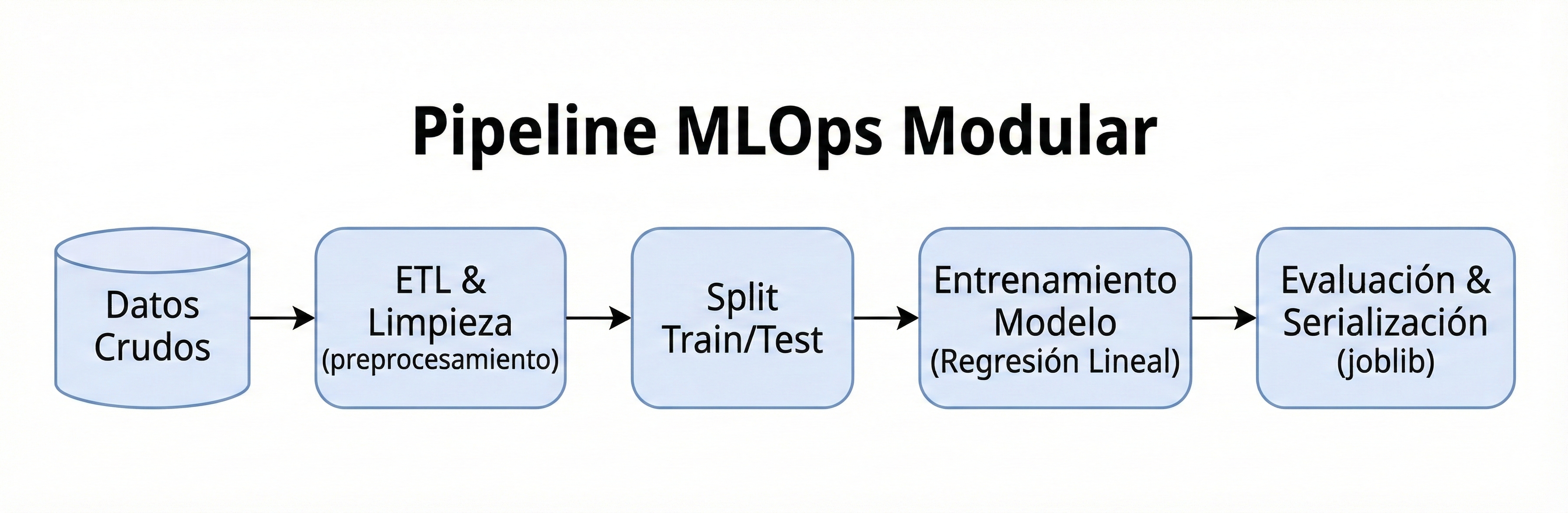
Desarrollo de un sistema modular de Machine Learning "End-to-End". Desde la ingeniería de datos hasta la predicción precisa, enfocado en código limpio y escalable.
Python
Scikit-learn
Pipeline Estructurado
Regresión Lineal
Pandas
.png)