La Importancia del ETL en Python
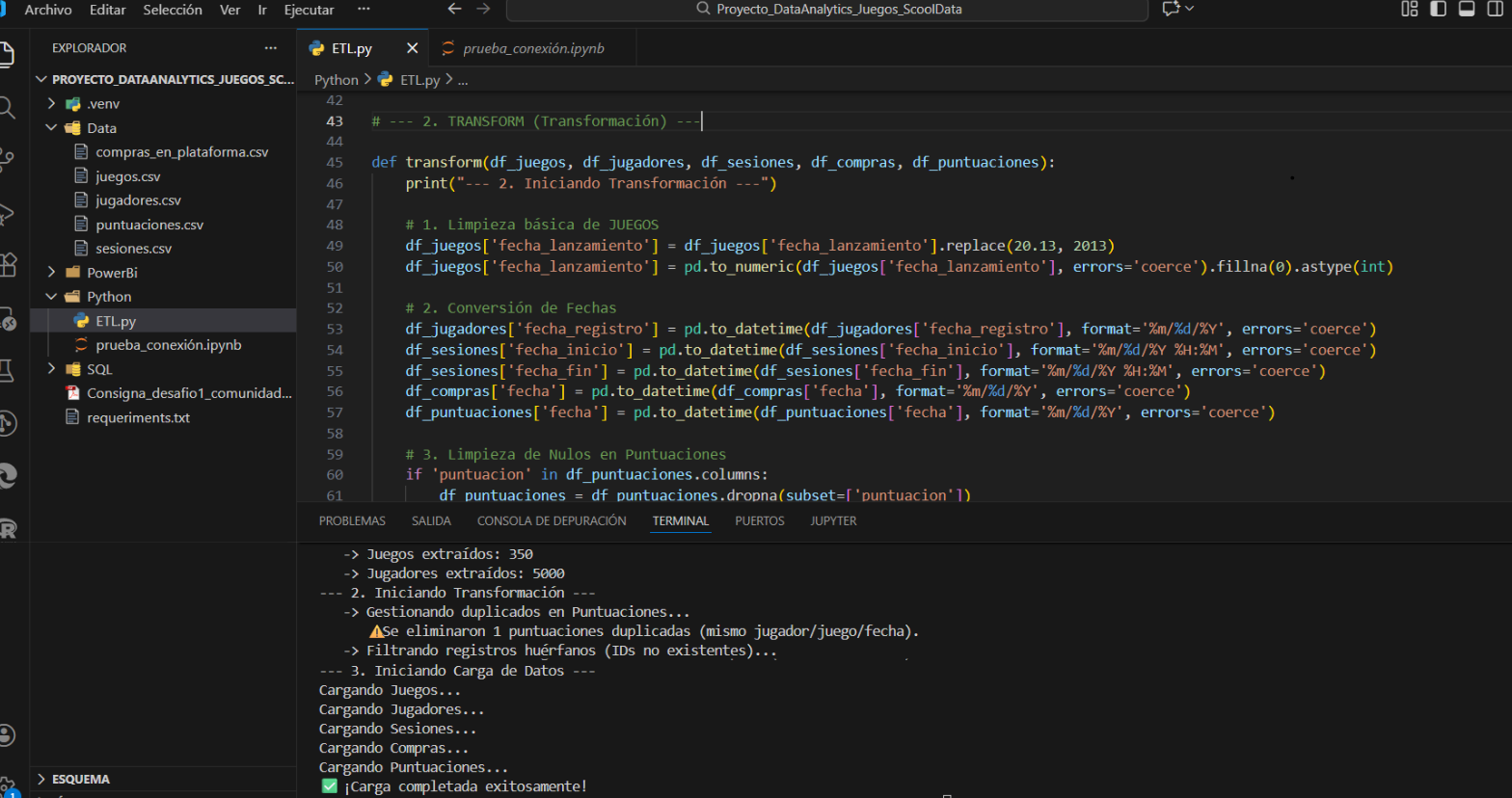
El proceso ETL en Python fue diseñado para blindar la calidad del dato ante los errores encontrados en los archivos crudos. Este flujo asegura que los datos que llegan a Power BI y SQL sean "Golden Records".
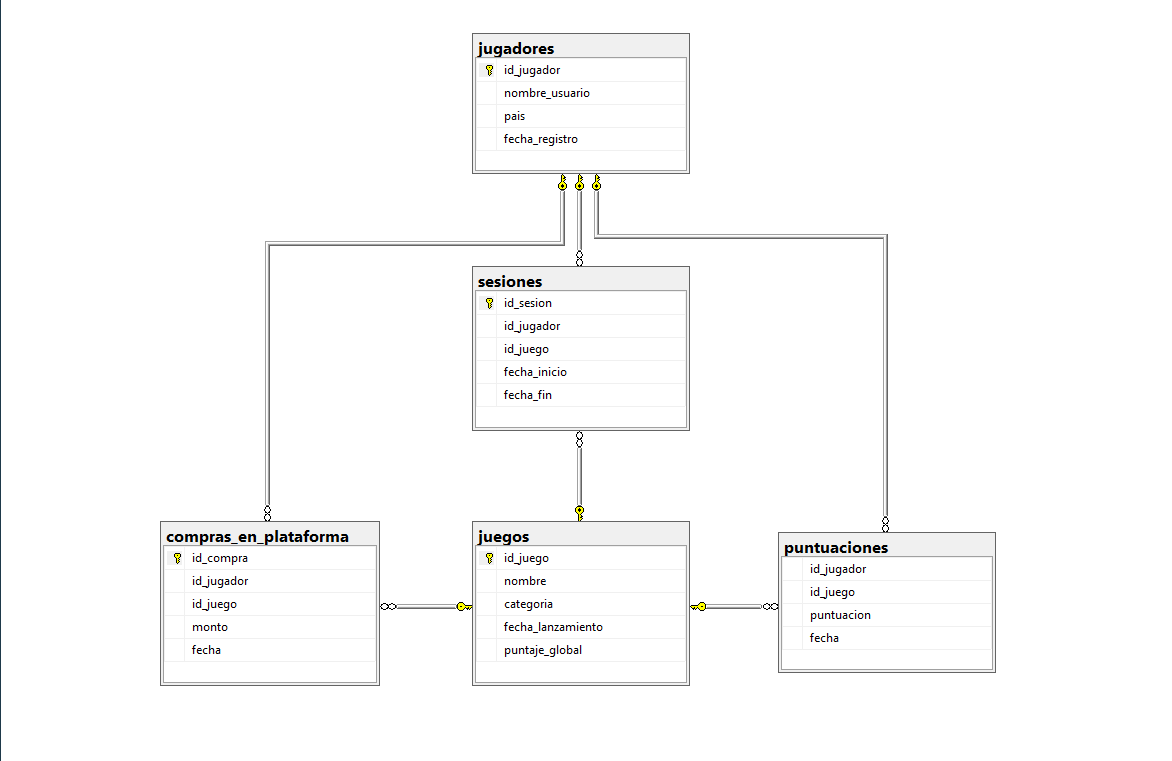
1. Integridad Referencial
Se eliminaron registros huérfanos (sesiones sin usuario) que corromperían el análisis de retención.
2. Lógica Temporal
Corrección de formatos de fecha para permitir cálculos de tiempo precisos (duración de sesiones).
3. Calidad Financiera
Eliminación de transacciones nulas y duplicados para asegurar KPIs de ingresos matemáticamente correctos.