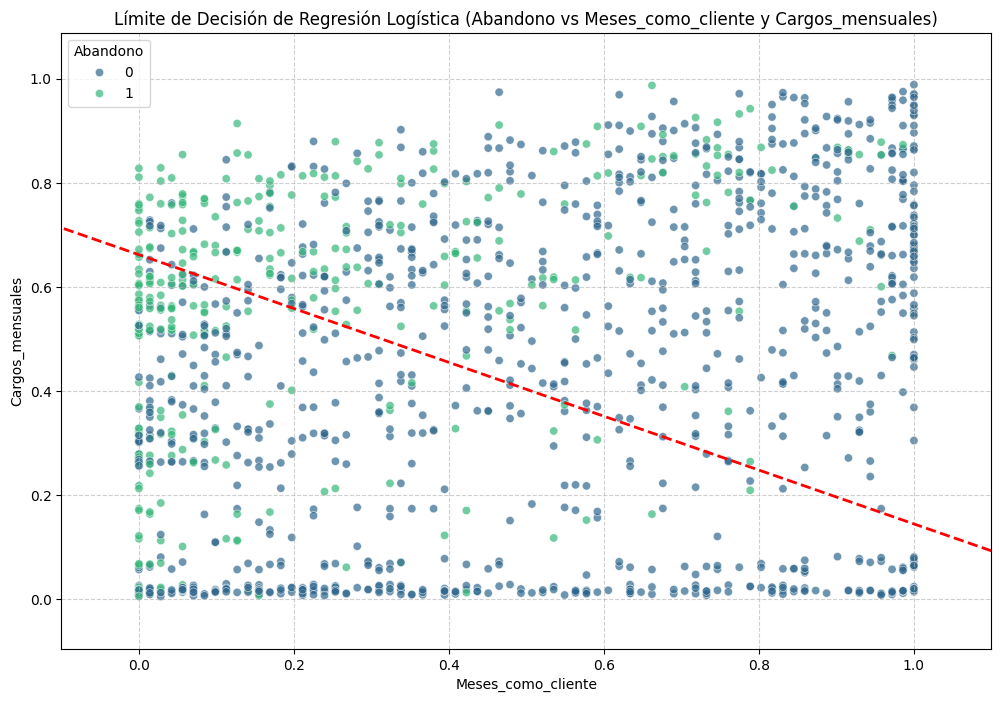
¿Qué impulsa el abandono?
El modelo no es una caja negra. Identificamos las variables con mayor peso predictivo para entender el comportamiento del cliente. El análisis reveló que el factor económico (Cargos Mensuales) y la antigüedad son determinantes. Además, ciertos servicios premium (Fibra Óptica, Streaming) muestran una correlación alta con la fuga, probablemente debido a ofertas competitivas o expectativas de calidad no cumplidas.